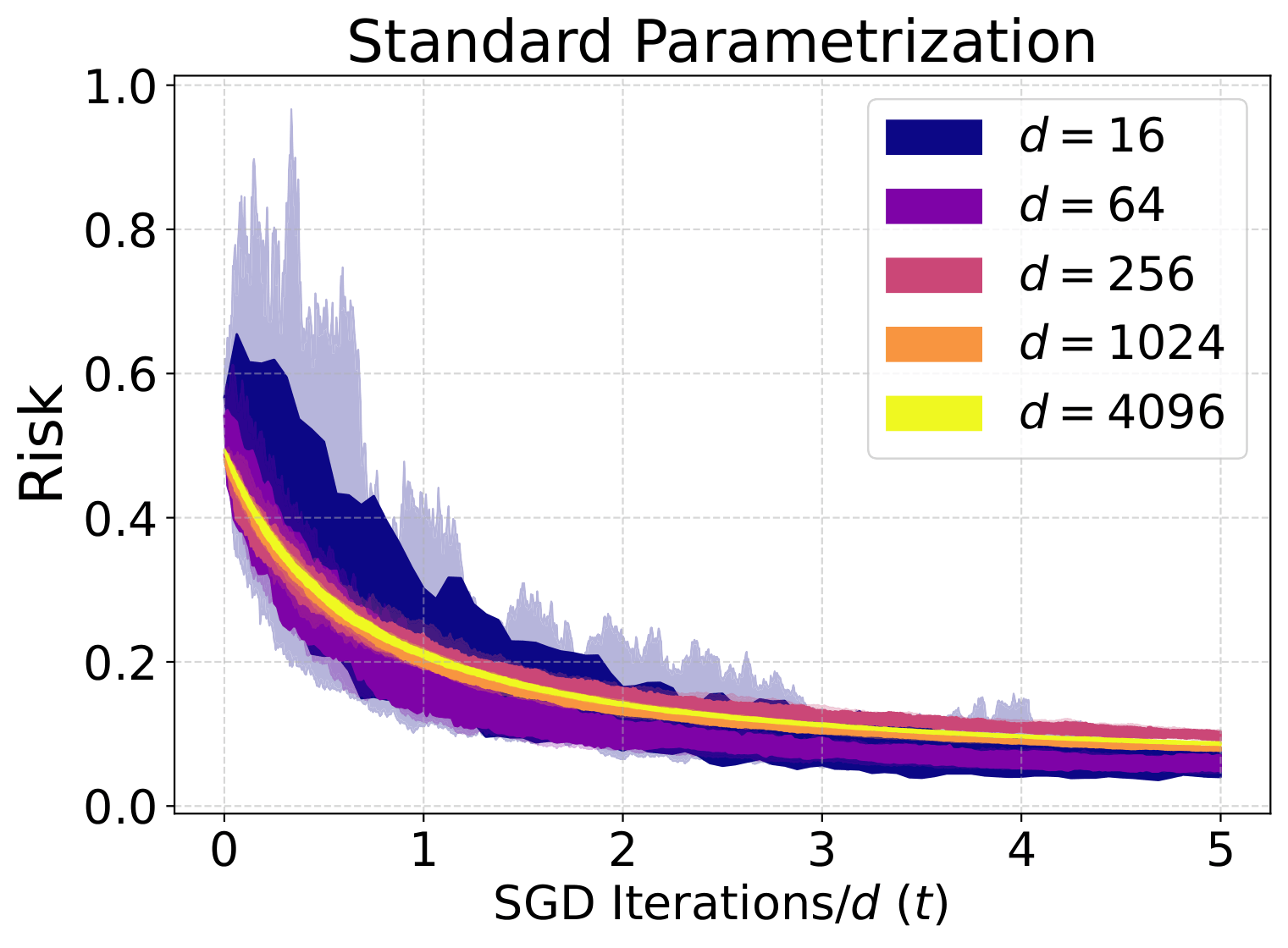
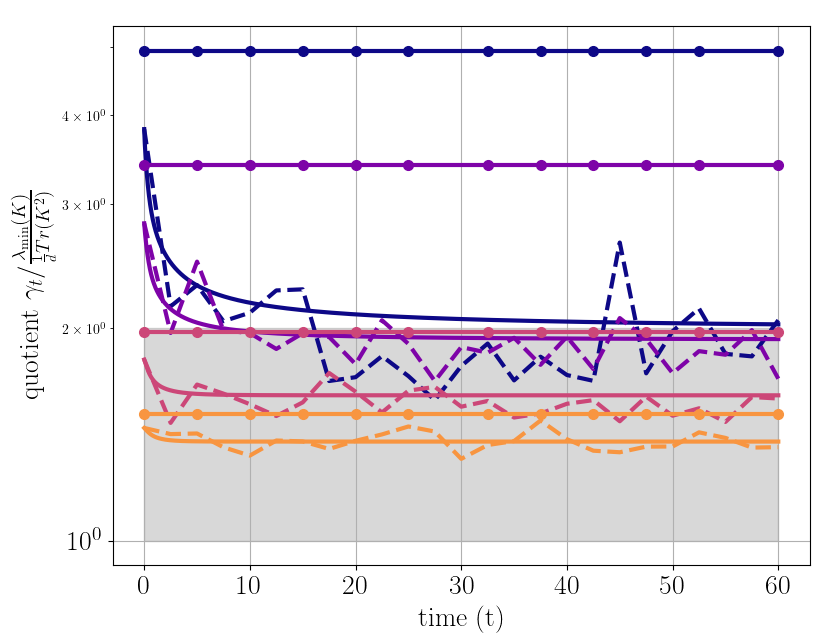
PROJECT PORTFOLIO
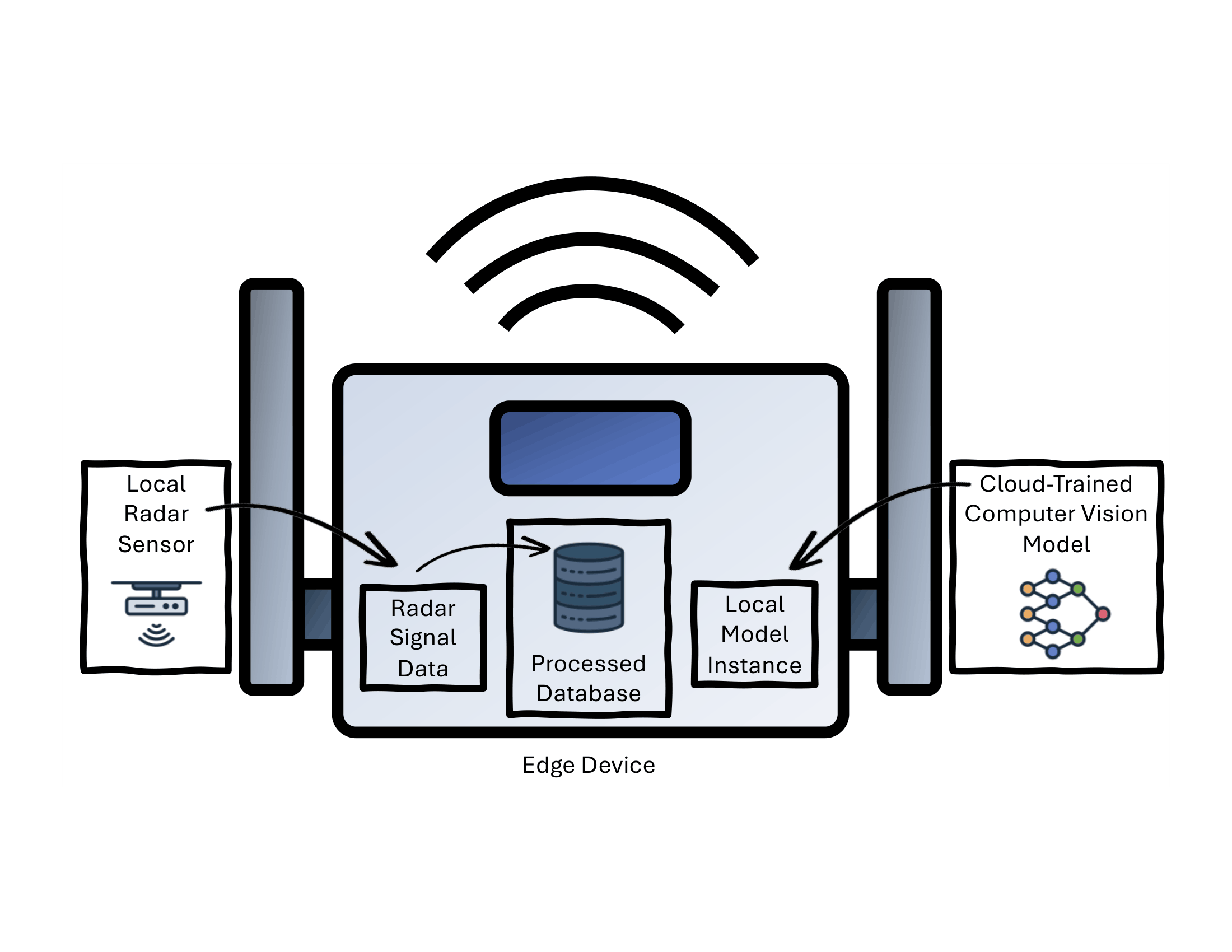
Edge Deployment Monitoring:
From Cloud Prototyping to Edge Execution
Begoña García Malaxechebarría, Daniel Ferguson
This project was developed during my summer internship at Microsoft
and is featured on the Data Science + AI at Microsoft blog.
Edge deployment monitoring studies how machine learning models behave after being transferred
from cloud development environments to local edge devices near the data source. In this project,
we designed a prototype architecture for monitoring edge AI deployments in remote settings, where
devices may operate with intermittent connectivity and where model performance depends not only on
predictive quality but also on device-specific constraints such as latency, throughput, and real-time
inference viability.
Our scenario considered radar-based drone-versus-bird detection using synthetic radar signals,
spectrogram generation, and a computer vision model deployed on an edge device. We focused on
identifying critical evaluation points across the inference pipeline, including signal processing,
image preprocessing, and model prediction, in order to benchmark performance and detect potential
bottlenecks. The project emphasized the importance of distinguishing device-independent metrics,
such as model version and training accuracy, from device-dependent metrics, such as inference latency
and throughput.
By combining local benchmarking with centralized aggregation of inference reports, the proposed
workflow enables site-specific insights to inform global model updates and operational decisions.
The project highlights how systematic monitoring, human-in-the-loop update strategies, and
performance profiling can support more reliable and scalable edge AI systems in real-world,
resource-constrained environments.
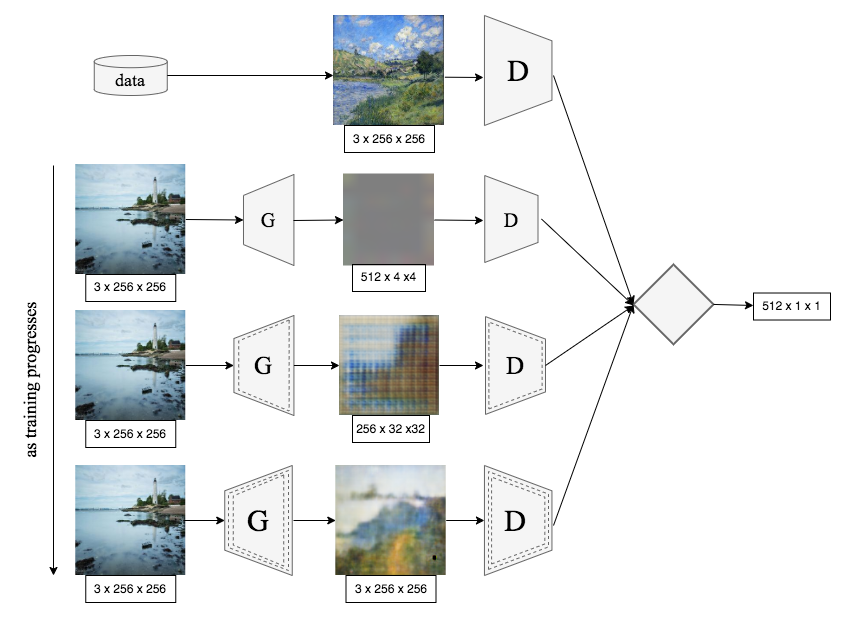
MonetGAN.
Painting with Generative Adversarial Networks:
Generating Monet-Style Images Using Novel Techniques
Garrett Devereux, Deekshita S. Doli, Begoña García Malaxechebarría
This project was developed as part of the graduate deep learning class at
University of Washington, instructed by Ranjay Krishna and Aditya Kusupati.
Generative Adversarial Networks (GANs) have emerged
as a powerful and versatile tool for generative modeling.
In recent years, they have gained significant popularity in
various research domains, particularly in image generation,
enabling researchers to address challenging problems
by generating realistic samples from complex data distributions.
In the art industry, where tasks often require significant
investments of time, labor, and creativity, there is a
growing need for more efficient approaches that can streamline
subsequent project phases. To this end, we present
MonetGAN, a pioneering framework based on the Least
Squares Deep Convolutional CycleGAN, specifically tailored to
generate images in the distinctive style of 19th-century renowned
painter Claude Monet. After achieving
non-trivial results with our baseline model, we explore the
integration of advanced techniques and architectures such
as ResNet Generators, a Progressive Growth Mechanism,
Differential Augmentation, and Dual-Objective Discriminators.
Through our research, we find that we can achieve
superior results with small changes to gradually build up
a successful model, rather than adding too many varying
complexities all at once. These outcomes underscore the intricacies
involved in the training of GANs, while also opening up promising
avenues for further advancements at the
intersection of art and artificial intelligence.